
CNN(1)
多层感知机十分适合处理表格数据,其中行对应样本,列对应特征。然而对于高维感知数据(图像),这种缺少结构的网络可能会变得不实用。
图像处理的问题
-
图像需要处理的数据量太大,导致成本很高,效率很低
图像是由像素构成的,每个像素又是由颜色构成的。如果一张图片像素为1000×1000,每个像素有RGB三个信息表示颜色信息,则一张图片需要处理三百万个参数。
**CNN 解决的第一个问题就是「将复杂问题简化」,把大量参数降维成少量参数,再做处理。**我们在大部分场景下,降维并不会影响结果。比如1000像素的图片缩小成200像素,并不影响肉眼认出来图片中是一只猫还是一只狗,机器也是如此。
-
图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
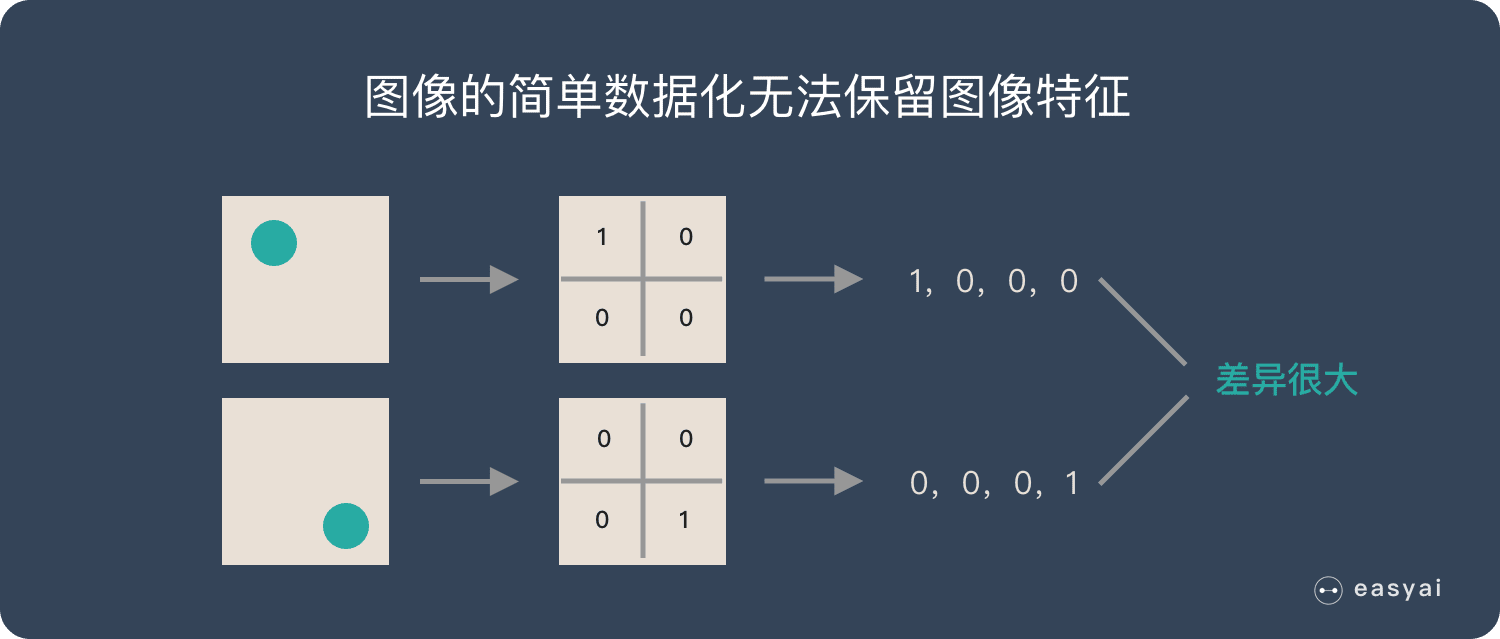
假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从视觉的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。
CNN用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
人类视觉原理
- 从原始信号摄入开始(瞳孔摄入像素 Pixels)
- 做初步处理(大脑皮层某些细胞发现边缘和方向)
- 抽象(大脑判定,眼前物体的形状,是圆形的)
- 进一步抽象(大脑进一步判定该物体是只气球)

卷积神经网络基本原理
典型的 CNN 由3个部分构成:
- 卷积层负责提取图像中的局部特征
- 池化层用来大幅降低参数量级(降维)
- 全连接层类似传统神经网络的部分,用来输出想要的结果
卷积:提取特征
使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
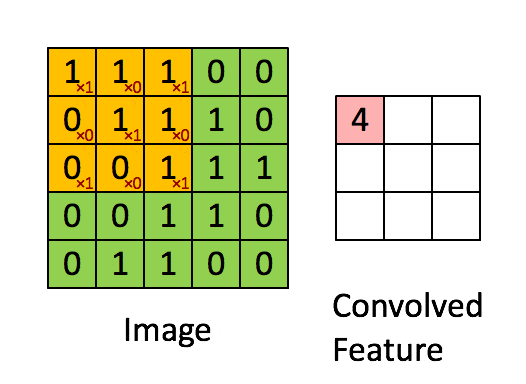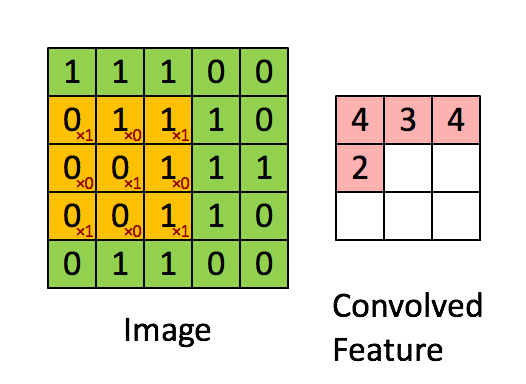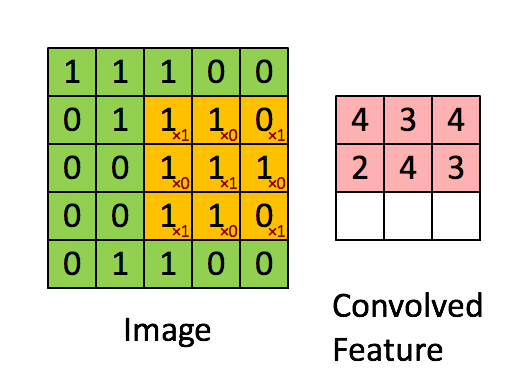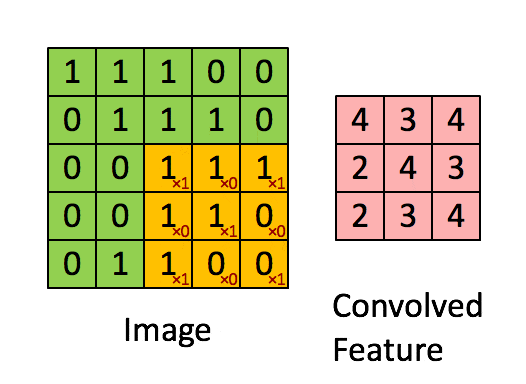
具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。
如果我们设计了6个卷积核,可以理解为:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。
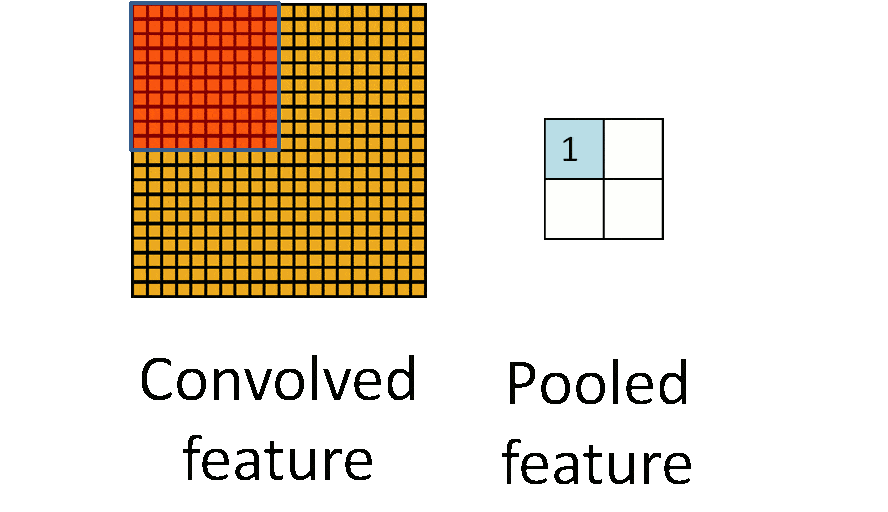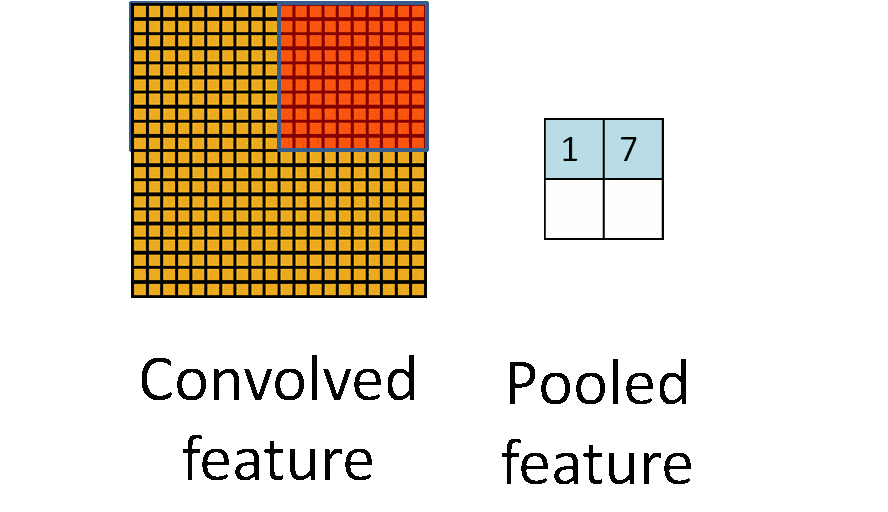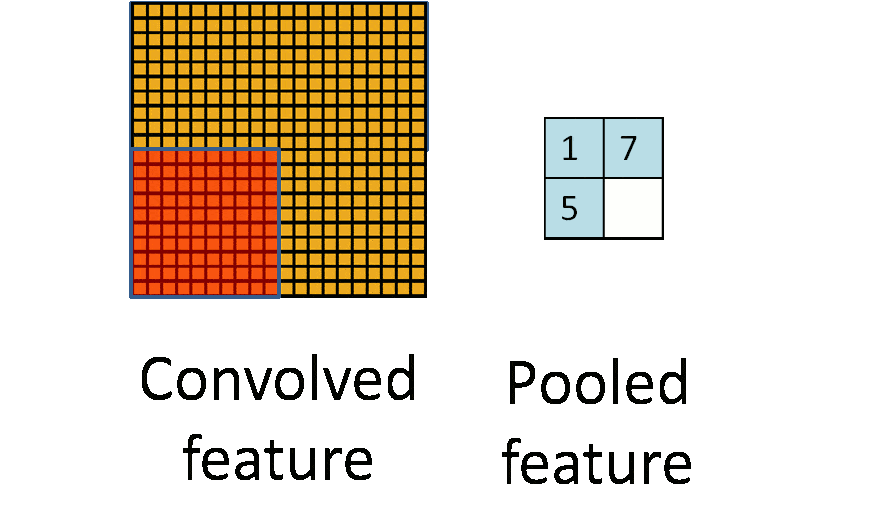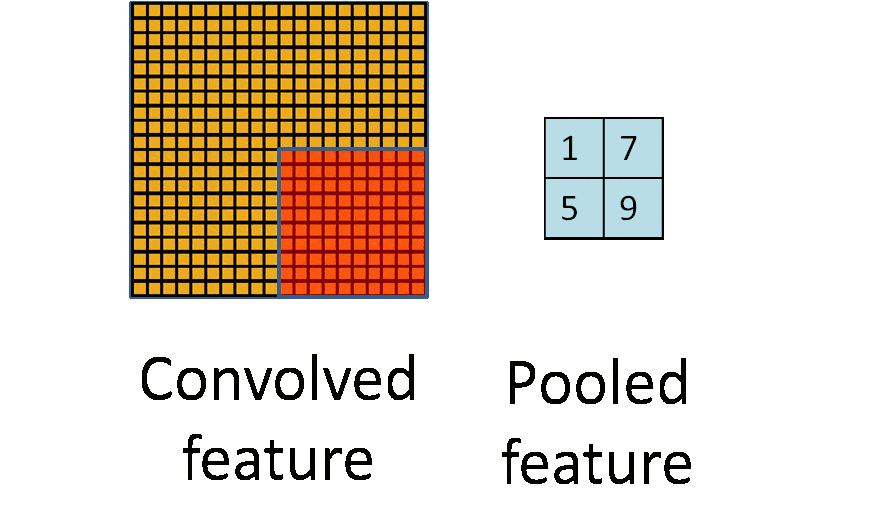
池化层(下采样):数据降维,避免过拟合
下图示例中:原始图片大小为20×20,对其进行下采样,采样窗口为10×10,最终将其下采样成为一个2×2大小的特征图。
对于每个窗口,挑选出最大的数值作为结果。
全连接层:输出结果
经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
LeNet-5
典型的卷积神经网络,其结构为:
卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层
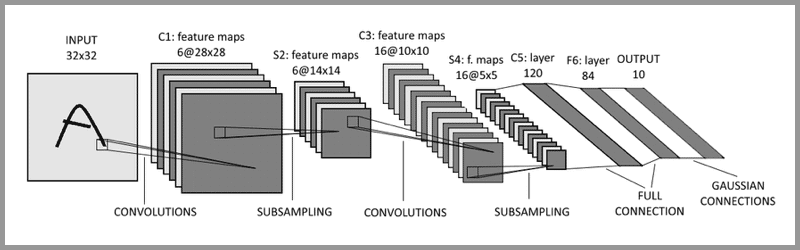
注意
卷积核是神经网络自己训练出来的,相当于一种“图像模式”,模型通过训练,得到一些特定的“图像模式”。训练好的模型通过这样的“知识”,来判断没有经过验证的图片的类型。