
Autograd Tutorial
1 | # For tips on running notebooks in Google Colab, see |
A Gentle Introduction to torch.autograd
torch.autograd is PyTorch’s automatic differentiation engine that powers neural network training. In this section, you will get a conceptual understanding of how autograd helps a neural network train.
Background:神经网络
Neural networks (NNs) are a collection of nested functions that are executed on some input data. These functions are defined by parameters (consisting of weights and biases), which in PyTorch are stored in tensors.
Training a NN happens in two steps:神经网络的训练
Forward Propagation: In forward prop, the NN makes its best guess about the correct output. It runs the input data through each of its functions to make this guess.
Backward Propagation: In backprop, the NN adjusts its parameters proportionate to the error in its guess. 在反向传播中,神经网络根据其猜测的误差按比例调整其参数。It does this by traversing backwards from the output, collecting the derivatives of the error with respect to the parameters of the functions (gradients), and optimizing the parameters using gradient descent. 它通过从输出向后遍历、收集误差相对于函数参数(梯度)的导数并使用梯度下降来优化参数来实现这一点。For a more detailed walkthrough of backprop, check out this video from 3Blue1Brown.
Usage in PyTorch
Let’s take a look at a single training step. For this example, we load a pretrained resnet18 model from torchvision. We create a random data tensor to represent a single image with 3 channels, and height & width of 64, and its corresponding label initialized to some random values. Label in pretrained models has shape (1,1000).
从 torchvision 加载预训练的 resnet18 模型。我们创建一个随机数据张量来表示具有 3 个通道、高度和宽度为 64 的单个图像,并将其相应的标签初始化为一些随机值。预训练模型中的标签形状为 (1,1000)。
This tutorial works only on the CPU and will not work on GPU devices (even if tensors are moved to CUDA).
1 | import torch |
Next, we run the input data through the model through each of its layers to make a prediction. This is the forward pass.
1 | prediction = model(data) # forward pass |
We use the model’s prediction and the corresponding label to calculate the error (loss). The next step is to backpropagate this error through the network. Backward propagation is kicked off when we call .backward() on the error tensor. Autograd then calculates and stores the gradients for each model parameter in the parameter’s .grad attribute.
我们使用模型的预测和相应的标签来计算误差(损失)。下一步是通过网络反向传播此错误。当我们对loss调用 .backward() 时,向后传播就开始了。然后,Autograd 计算每个模型参数的梯度并将其存储在参数的 .grad 属性中。
1 | loss = (prediction - labels).sum() |
Next, we load an optimizer, in this case SGD with a learning rate of 0.01 and momentum of 0.9. We register all the parameters of the model in the optimizer.
接下来,我们加载优化器,在本例中为 SGD,学习率为 0.01,动量为 0.9。我们在优化器中注册模型的所有参数。
Q:momentum?
1 | optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9) |
Finally, we call .step() to initiate gradient descent. The optimizer adjusts each parameter by its gradient stored in .grad.
最后,我们调用 .step() 来启动梯度下降。优化器通过存储在 .grad 中的梯度来调整每个参数。
1 | optim.step() #gradient descent |
At this point, you have everything you need to train your neural network. The below sections detail the workings of autograd - feel free to skip them.
以下部分详细介绍了 autograd 的工作原理。
Differentiation in Autograd
Let’s take a look at how autograd collects gradients. We create two tensors a and b with requires_grad=True. This signals to autograd that every operation on them should be tracked.
requires_grad=True标志着tensor会在backward时自动微分,并将梯度记录。
1 | import torch |
We create another tensor Q from a and b.
1 | Q = 3*a**3 - b**2 |
Let’s assume a and b to be parameters of an NN, and Q to be the error. In NN training, we want gradients of the error w.r.t. parameters, i.e.
假设a and b 是神经网络的参数,Q为error,则梯度计算如下:
When we call .backward() on Q, autograd calculates these gradients and stores them in the respective tensors’ .grad attribute.
在Q上调用.backward()时,autograd计算上述梯度并将其存储到参数的grad属性中。
We need to explicitly pass a gradient argument in Q.backward() because it is a vector. gradient is a tensor of the same shape as Q, and it represents the gradient of Q w.r.t. itself, i.e.
我们需要在 Q.backward() 中显式传递梯度参数,因为它是一个向量。gradient 是与 Q 形状相同的张量, 它代表 Q 相对于自身的梯度。
Equivalently, we can also aggregate Q into a scalar and call backward implicitly, like Q.sum().backward().
同样,我们也可以将 Q 聚合为标量并隐式调用backward。
1 | external_grad = torch.tensor([1., 1.]) |
Gradients are now deposited in a.grad and b.grad
梯度现在存放在“a.grad”和“b.grad”中
1 | # check if collected gradients are correct |
tensor([True, True])
tensor([True, True])
Optional Reading - Vector Calculus using autograd
Mathematically, if you have a vector valued function , then the gradient of with respect to is a Jacobian matrix :输入、输出都为向量时,梯度的计算
Generally speaking, torch.autograd is an engine for computing vector-Jacobian product. That is, given any vector , compute the product
If happens to be the gradient of a scalar function :
then by the chain rule, the vector-Jacobian product would be the gradient of with respect to :
This characteristic of vector-Jacobian product is what we use in the above example; external_grad represents .
Computational Graph:计算图
Conceptually, autograd keeps a record of data (tensors) & all executed operations (along with the resulting new tensors) in a directed acyclic graph (DAG) consisting of Function objects. In this DAG, leaves are the input tensors, roots are the output tensors. By tracing this graph from roots to leaves, you can automatically compute the gradients using the chain rule.
从概念上讲,autograd 在由 Function 对象组成的有向无环图 (DAG) 中保存数据(张量)和所有执行的操作(以及生成的新张量)的记录。在这个 DAG 中,叶子是输入张量,根是输出张量。通过从根到叶追踪该图,您可以使用链式法则自动计算梯度。
In a forward pass, autograd does two things simultaneously:
- run the requested operation to compute a resulting tensor, and
- maintain the operation’s gradient function in the DAG.
在前向传递中,autograd 同时执行两件事: 运行请求的操作来计算结果张量,并且 在 DAG 中维护操作的梯度函数。
The backward pass kicks off when .backward() is called on the DAG root. autograd then:
- computes the gradients from each
.grad_fn, - accumulates them in the respective tensor’s
.gradattribute, and - using the chain rule, propagates all the way to the leaf tensors.
当在 DAG 根上调用 .backward() 时,向后传递开始。然后自动毕业: 计算每个 .grad_fn 的梯度, 将它们累积到各自张量的 .grad 属性中,并且 使用链式法则,一直传播到叶张量。
Below is a visual representation of the DAG in our example. In the graph, the arrows are in the direction of the forward pass. The nodes represent the backward functions of each operation in the forward pass. The leaf nodes in blue represent our leaf tensors a and b.
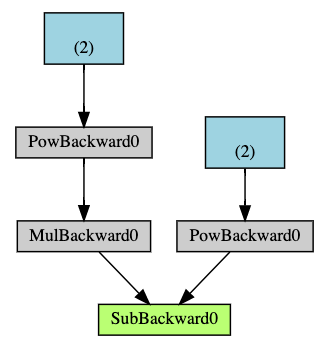
下面是我们示例中 DAG 的直观表示。图中,箭头指向前向传播的方向。节点代表前向传播中每个操作的backward函数。蓝色的叶节点代表我们的叶张量 a 和 b。
An important thing to note is that the graph is recreated from scratch; after each.backward() call, autograd starts populating a new graph. This is exactly what allows you to use control flow statements in your model;you can change the shape, size and operations at every iteration if needed.
需要注意的重要一点是,该图是从头创建的;每次 .backward() 调用后,autograd 开始填充新图表。这正是允许您在模型中使用控制流语句的原因;如果需要,您可以在每次迭代时更改形状、大小和操作。
Exclusion from the DAG
torch.autograd tracks operations on all tensors which have their requires_grad flag set to True. For tensors that don’t require gradients, setting this attribute to False excludes it from the gradient computation DAG.
torch.autograd 跟踪所有 require_grad 标志设置为 True 的张量上的操作。对于不需要梯度的张量,将此属性设置为 False 会将其从梯度计算 DAG 中排除。
The output tensor of an operation will require gradients even if only a single input tensor has requires_grad=True.
即使只有一个输入张量 require_grad=True,操作的输出张量也将需要梯度。
1 | x = torch.rand(5, 5) |
Does `a` require gradients?: False
Does `b` require gradients?: True
In a NN, parameters that don’t compute gradients are usually called frozen parameters. It is useful to “freeze” part of your model if you know in advance that you won’t need the gradients of those parameters (this offers some performance benefits by reducing autograd computations).
在神经网络中,不计算梯度的参数通常称为冻结参数。如果您事先知道不需要这些参数的梯度,那么“冻结”模型的一部分很有用(这通过减少自动梯度计算提供了一些性能优势)。
In finetuning, we freeze most of the model and typically only modify the classifier layers to make predictions on new labels. Let’s walk through a small example to demonstrate this. As before, we load a pretrained resnet18 model, and freeze all the parameters.
在微调中,我们冻结大部分模型,通常只修改分类器层以对新标签进行预测。让我们通过一个小例子来演示这一点。和之前一样,我们加载预训练的 resnet18 模型,并冻结所有参数。
1 | from torch import nn, optim |
Let’s say we want to finetune the model on a new dataset with 10 labels. In resnet, the classifier is the last linear layer model.fc. We can simply replace it with a new linear layer (unfrozen by default) that acts as our classifier.
假设我们想要在具有 10 个标签的新数据集上微调模型。在resnet中,分类器是最后一个线性层model.fc。我们可以简单地用一个新的线性层(默认情况下未冻结)替换它作为我们的分类器。
1 | model.fc = nn.Linear(512, 10) |
Now all parameters in the model, except the parameters of model.fc, are frozen. The only parameters that compute gradients are the weights and bias of model.fc.
现在模型中的所有参数(除了 model.fc 的参数)都被冻结。计算梯度的唯一参数是 model.fc 的 weights
and bias。
1 | # Optimize only the classifier |
Notice although we register all the parameters in the optimizer, the only parameters that are computing gradients (and hence updated in gradient descent) are the weights and bias of the classifier.
The same exclusionary functionality is available as a context manager in torch.no_grad()
相同的排除功能可用作 torch.no_grad() 中的上下文管理器