
CIFAR10 Tutorial
1 | # For tips on running notebooks in Google Colab, see |
Training a Classifier
This is it. You have seen how to define neural networks, compute loss and make updates to the weights of the network.
已经了解了如何定义神经网络、计算损失以及更新网络权重。
Now you might be thinking, What about data?如何处理不同的数据类型
Generally, when you have to deal with image, text, audio or video data, you can use standard python packages that load data into a numpy array. Then you can convert this array into a torch.*Tensor.
- For images, packages such as Pillow, OpenCV are useful;图片可以使用的包
- For audio, packages such as scipy and librosa;音频可以使用的包
- For text, either raw Python or Cython based loading, or NLTK and SpaCy are useful;文本可以使用的包
Specifically for vision, we have created a package called torchvision, that has data loaders for common datasets such as ImageNet, CIFAR10, MNIST, etc. and data transformers for images, viz., torchvision.datasets and torch.utils.data.DataLoader.
针对图像处理,我们创建了一个名为“torchvision”的包,其中包含用于常见数据集(例如 ImageNet、CIFAR10、MNIST 等)的数据加载器以及用于图像的数据转换器,即“torchvision.datasets”和“torch.utils” .data.DataLoader`。
This provides a huge convenience and avoids writing boilerplate code.
For this tutorial, we will use the CIFAR10 dataset. It has the classes: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’. The images in CIFAR-10 are of size 3x32x32, i.e. 3-channel color images of 32x32 pixels in size.
在本教程中,我们将使用 CIFAR10 数据集。它的分类有:“飞机”、“汽车”、“鸟”、“猫”、“鹿”、“狗”、“青蛙”、“马”、“船”、“卡车”。 CIFAR-10中的图像尺寸为3x32x32,即尺寸为32x32像素的3通道彩色图像。

Training an image classifier
We will do the following steps in order:
通过下面几步训练一个图片分类器:
- Load and normalize the CIFAR10 training and test datasets using
torchvision;加载并规范化数据集 - Define a Convolutional Neural Network;定义卷积神经网络
- Define a loss function;定义损失函数
- Train the network on the training data;训练
- Test the network on the test data;测试
1. Load and normalize CIFAR10
Using torchvision, it’s extremely easy to load CIFAR10.使用torchvision模块加载CIFAR10数据集
1 | import torch |
The output of torchvision datasets are PILImage images of range [0, 1]. We transform them to Tensors of normalized range [-1, 1].
torchvision数据集的输出是范围 [0, 1] 的 PILImage 图像。我们将它们归一化为范围 [-1, 1] 的张量。
If running on Windows and you get a BrokenPipeError, try settingthe num_worker of torch.utils.data.DataLoader() to 0.如果在 Windows 上运行并且出现 BrokenPipeError,请尝试将 torch.utils.data.DataLoader() 的 num_worker 设置为 0。
1 | transform = transforms.Compose( |
Files already downloaded and verified
Files already downloaded and verified
transforms.ToTensor():
这个步骤将图像转换为 PyTorch 张量。图像的像素值通常是范围在 [0, 255] 的整数,通过这个转换,像素值会被标准化为 [0.0, 1.0] 之间的浮点数。
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)):
这个步骤对张量进行归一化。它使用给定的均值和标准差来调整像素值。这里的 (0.5, 0.5, 0.5) 代表图像的三个通道(通常是红、绿、蓝)的均值和标准差,分
别是 0.5。归一化的操作是将像素值从 [0.0, 1.0] 范围调整到 [-1.0, 1.0] 范围。
归一化的公式如下:
设置
mean=0.5,std=0.5,对于一个像素值为1.0的店:
对于一个像素值为
0.0的点:
Let us show some of the training images, for fun.
1 | import matplotlib.pyplot as plt |
torch.Size([4, 3, 32, 32])
torch.Size([4])
tensor([6, 1, 2, 6])
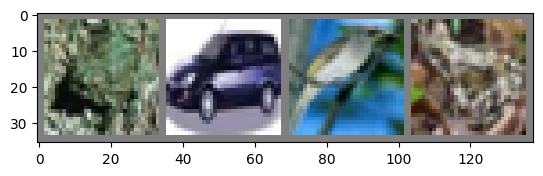
frog car bird frog
-
Define a Convolutional Neural Network
Copy the neural network from the Neural Networks section before and modify it to take 3-channel images (instead of 1-channel images as it was defined).
1 | import torch.nn as nn |
-
Define a Loss function and optimizer
Let’s use a Classification Cross-Entropy loss and SGD with momentum.
1 | import torch.optim as optim |
-
Train the network
This is when things start to get interesting. We simply have to loop over our data iterator, and feed the inputs to the network and optimize.
1 | for epoch in range(2): # loop over the dataset multiple times;epoch:0,1 |
[1, 2000] loss: 2.216
[1, 4000] loss: 1.885
[1, 6000] loss: 1.701
[1, 8000] loss: 1.609
[1, 10000] loss: 1.556
[1, 12000] loss: 1.486
[2, 2000] loss: 1.422
[2, 4000] loss: 1.397
[2, 6000] loss: 1.353
[2, 8000] loss: 1.344
[2, 10000] loss: 1.307
[2, 12000] loss: 1.306
Finished Training
Let’s quickly save our trained model:
1 | PATH = './cifar_net.pth' |
See here for more details on saving PyTorch models.
-
Test the network on the test data
We have trained the network for 2 passes over the training dataset. But we need to check if the network has learnt anything at all.
我们已经在训练数据集上对网络进行了 2 次训练(epoch)。但我们需要检查网络是否学到了任何东西。
We will check this by predicting the class label that the neural network outputs, and checking it against the ground-truth. If the prediction is correct, we add the sample to the list of correct predictions.
我们将通过预测神经网络输出的类标签并根据真实情况进行检查来检查这一点。如果预测正确,我们会将样本添加到正确预测列表中。
Okay, first step. Let us display an image from the test set to get familiar.
显示测试集中的图像以熟悉一下。
1 | dataiter = iter(testloader) |
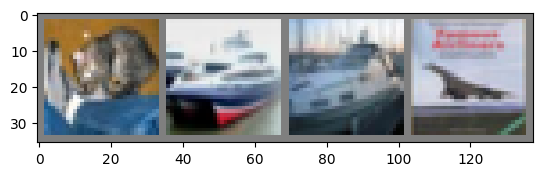
GroundTruth: cat ship ship plane
Next, let’s load back in our saved model (note: saving and re-loading the model wasn’t necessary here, we only did it to illustrate how to do so):
接下来,让我们加载回已保存的模型(注意:保存并重新加载模型不是必须的,我们这样做只是为了说明如何执行此操作):
1 | net = Net() |
<All keys matched successfully>
Okay, now let us see what the neural network thinks these examples above are:
1 | outputs = net(images) |
tensor([[-0.1879, -0.3676, 0.2253, 1.2256, 0.0835, 0.2788, 1.4180, -1.7503,
0.1457, -0.8939],
[ 4.6166, 7.0969, -1.9678, -3.6791, -2.9520, -4.4108, -4.3927, -4.0881,
6.0323, 4.0923],
[ 2.9825, 2.3304, -0.2517, -1.8886, -0.0883, -2.2235, -2.7187, -1.5714,
2.8798, 0.8799],
[ 3.1114, 3.2242, -1.1028, -2.2863, -0.0712, -2.7737, -2.7508, -2.1876,
3.3800, 1.7259]], grad_fn=<AddmmBackward0>)
torch.Size([4, 10])
The outputs are energies for the 10 classes. The higher the energy for a class, the more the network thinks that the image is of the particular class. So, let’s get the index of the highest energy:输出是 10 个类别的概率。类别的概率越高,网络越认为该图像属于特定类别。那么,让我们得到最高概率的索引:
1 | _, predicted = torch.max(outputs, 1)# 从第1个维度(每一行)挑选出最大的值 |
torch.return_types.max(
values=tensor([1.4180, 7.0969, 2.9825, 3.3800], grad_fn=<MaxBackward0>),
indices=tensor([6, 1, 0, 8]))
Predicted: frog car plane ship
The results seem pretty good.
Let us look at how the network performs on the whole dataset.
1 | correct = 0 |
Accuracy of the network on the 10000 test images: 50 %
That looks way better than chance, which is 10% accuracy (randomly picking a class out of 10 classes). Seems like the network learnt something.
这看起来比随机要好得多,概率为 10%(从 10 个类别中随机选择一个类别)。看来网络学到了一些东西。
Hmmm, what are the classes that performed well, and the classes that did not perform well:
哪些类别表现良好,哪些类别表现不佳?
1 | # prepare to count predictions for each class |
Accuracy for class: plane is 53.6 %
Accuracy for class: car is 87.1 %
Accuracy for class: bird is 35.8 %
Accuracy for class: cat is 14.2 %
Accuracy for class: deer is 68.1 %
Accuracy for class: dog is 23.3 %
Accuracy for class: frog is 56.8 %
Accuracy for class: horse is 70.2 %
Accuracy for class: ship is 58.3 %
Accuracy for class: truck is 37.1 %
Okay, so what next?
How do we run these neural networks on the GPU?
Training on GPU
Just like how you transfer a Tensor onto the GPU, you transfer the neural net onto the GPU.
就像将张量传输到 GPU 上一样,将神经网络传输到 GPU 上。
Let’s first define our device as the first visible cuda device if we have CUDA available:
如果我们有可用的 CUDA,我们首先将我们的设备定义为第一个可见的 cuda 设备:
1 | device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') |
cuda:0
The rest of this section assumes that device is a CUDA device.
本节的其余部分假设“device”是 CUDA 设备。
Then these methods will recursively go over all modules and convert their parameters and buffers to CUDA tensors:
这些方法将递归地遍历所有模块并将它们的参数和缓冲区转换为 CUDA 张量:
1 | net.to(device) |
Remember that you will have to send the inputs and targets at every step to the GPU too:
请记住,您还必须将每一步的输入和目标发送到 GPU:
1 | inputs, labels = data[0].to(device), data[1].to(device) |
Why don’t I notice MASSIVE speedup compared to CPU? Because your network is really small.
与 CPU 相比,为什么我没有注意到大幅加速?因为这个网络实在是太小了。
Exercise: Try increasing the width of your network (argument 2 of the first nn.Conv2d, and argument 1 of the second nn.Conv2d – they need to be the same number), see what kind of speedup you get.
尝试增加网络的复杂度(第一个 nn.Conv2d 的参数 2 和第二个 nn.Conv2d 的参数 1 - 它们需要是相同的数字),看看加速效果。
Goals achieved:
- Understanding PyTorch’s Tensor library and neural networks at a high level.深入了解 PyTorch 的 Tensor 库和神经网络。
- Train a small neural network to classify images;训练小型神经网络对图像进行分类。
Training on multiple GPUs在多个 GPU 上进行训练
If you want to see even more MASSIVE speedup using all of your GPUs, please check out data_parallel_tutorial{.interpreted-text role=“doc”}.如果希望使用更多 GPU 获得更大的加速,请查看 data_parallel_tutorial{.interpreted-text role=“doc”}。
Where do I go next?
Train neural nets to play video games </intermediate/reinforcement_q_learning>{.interpreted-text
role=“doc”}- Train a state-of-the-art ResNet network on imagenet
- Train a face generator using Generative Adversarial Networks
- Train a word-level language model using Recurrent LSTM networks
- More examples
- More tutorials
- Discuss PyTorch on the Forums
- Chat with other users on Slack
1 | del dataiter |