
PyTorch:优化器
随机梯度下降SGD
每次更新的时候使用一个样本进行梯度下降,所谓的随机二字,就是说我们可以随机用一个样本来表示所有的样本,来调整超参数。
1 | import torch.optim as optim |
momentum
如图所示,红色为SGD+Momentum。黑色为SGD。可以看到黑色为典型Hessian矩阵病态的情况,相当于大幅度的徘徊着向最低点前进。
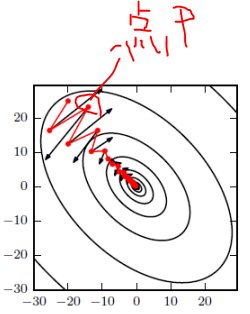
由于动量积攒了历史的梯度,如点P前一刻的梯度与当前的梯度方向几乎相反。因此原本在P点原本要大幅徘徊的梯度,主要受到前一时刻的影响,而导致在当前时刻的梯度幅度减小。
直观上讲就是,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。
梯度更新公式变化如下:可以想象成“方向速度”,与上一次的更新有关。如果上一次梯度与此次方向相同,则会越来越大,的更新也越开越快;反之变小,的更新梯度也变小。可以视作空气阻力/地面摩擦力,通常设置为0.9。
评论