
torch.nn Tutorial
torch.nn用法
nn.Linear
函数原型
1 | class nn.Linear(in_features, |
参数含义
- in_features:输入张量的长度
- out_features:输出张量的长度
- bias:是否包含偏置量
原理
为模型要学习的参数,为偏置向量,为输出向量的行数(例如,你想一次输入10个样本,即 为10,则=10),为输入神经元的个数(例如,输入的样本特征数为5,则=5),为输出神经元的个数。
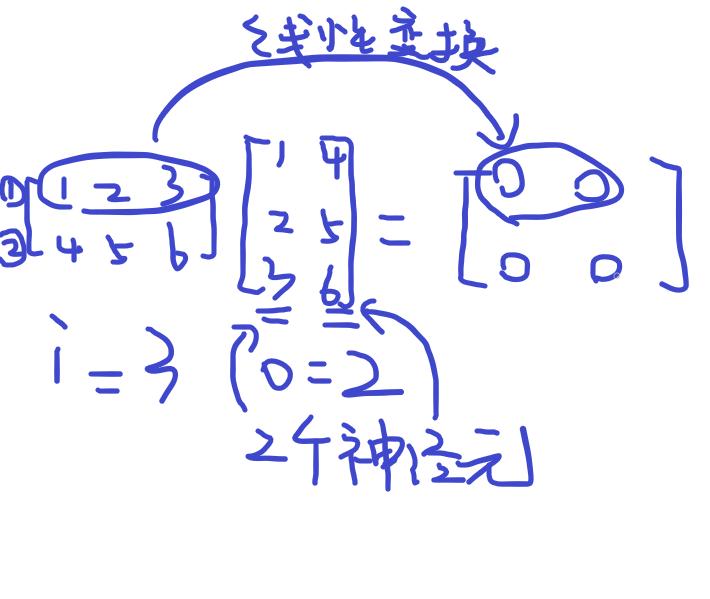
实例
假设我们的一次输入三个样本A,B,C(即batch_size为3),每个样本的特征数量为5:
1 | A: [0.1,0.2,0.3,0.3,0.3] |
则我们的输入向量 为:
1 | X = torch.Tensor([ |
定义线性层,我们的输入特征为5,所以in_features=5,令下一层的神经元个数为10,所以out_features=10,则模型参数为:
1 | model = nn.Linear(in_features=5, out_features=10, bias=True) |
因为有三个样本,所以相当于依次进行了三次 ,然后再将三个 叠在一起。经过线性层后,我们最终得到了形状为 的矩阵。即输入3个样本,每个样本维度为5;输出为3个样本,将每个样本扩展成了10维。
1 | model(X).size(10) |
nn.Conv2d
函数原型
1 | class torch.nn.Conv2d(in_channels, |
参数含义
-
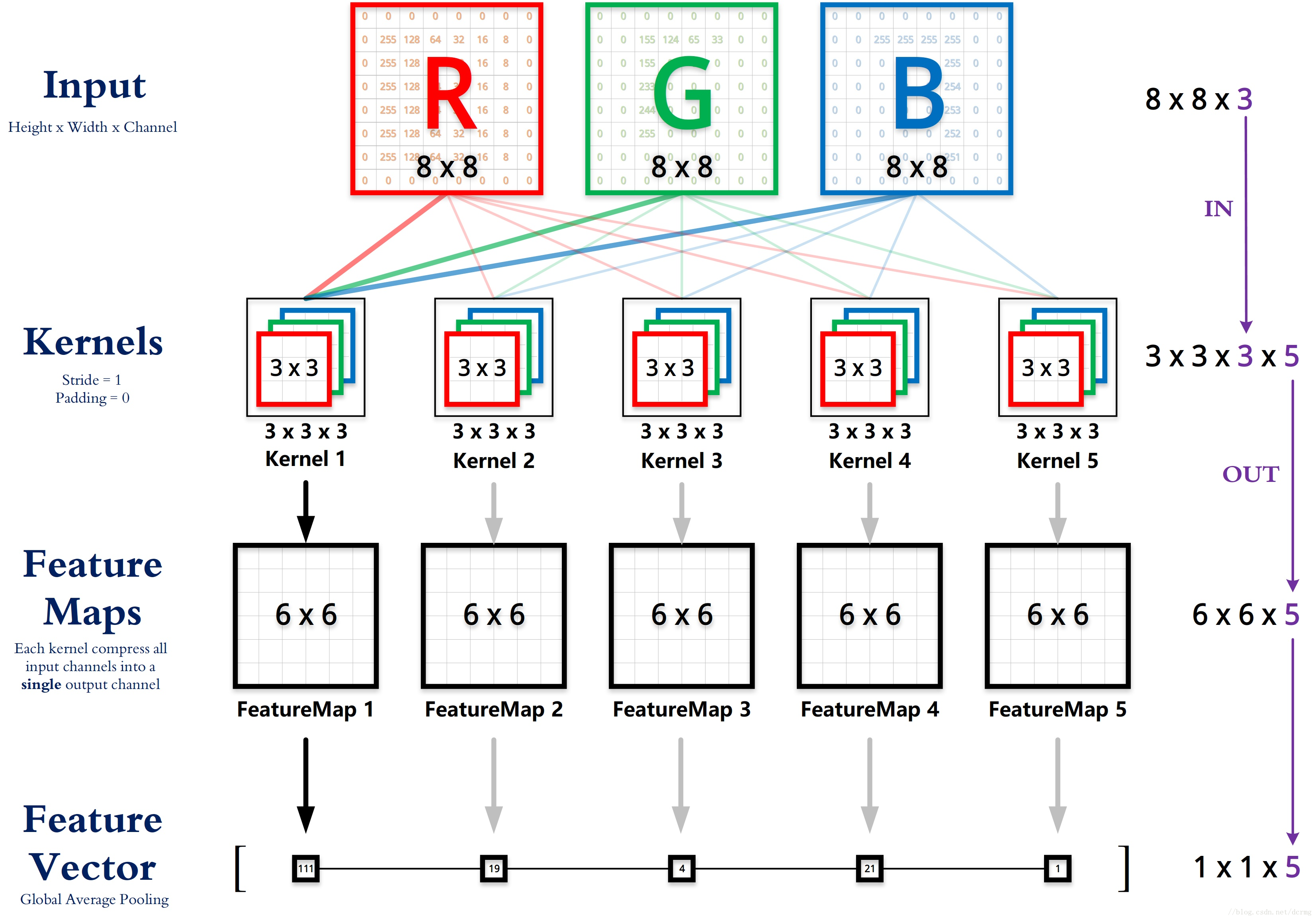
in_channels:输入图像的通道数
-
out_channels:卷积产生的通道数
-
kernel_size:卷积核尺寸,可以设为1个int型数或者一个(int, int)型的元组,例如(2,3)是高2宽3卷积核
-
stride:卷积步长,默认为1
-
padding:在输入张量的边缘添加额外的零值(或其他值),以控制输出张量的空间尺寸。有助于保持卷积后的特征图大小与输入图像相同,或者减小卷积操作的空间尺寸缩小效果。
1
2
3padding=0 # 无填充
padding=1 # 在输入张量的每一边加一个零
padding="same" # 使得输出尺寸与输入尺寸相同 -
- zeros(常量填充),默认情况是使用0填充,可选择整形int或者tuple元组
- reflect(反射填充),以矩阵中的某个行或列为轴,中心对称的padding到最外围
- replicate(复制填充),replicate将矩阵的边缘复制并填充到矩阵的外围
- circular(循环填充),从上到下进行无限的重复延伸
-
dilation:扩张卷积,普通的卷积是“密实”的,扩张卷积可以在不改变训练参数量的前提下,增加卷积核的感受域。
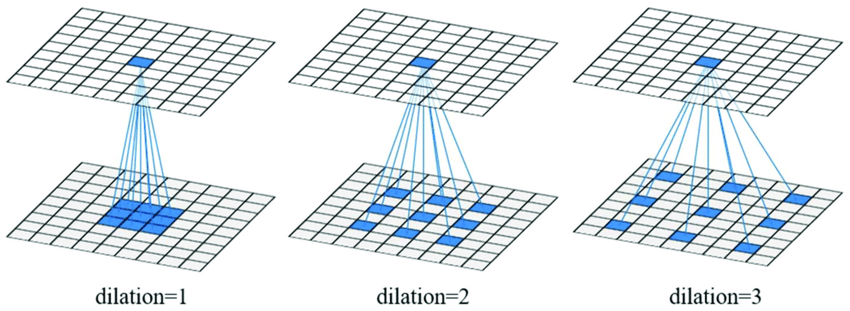
-
groups:控制分组卷积。输入in_channels被划分为groups组, 每组通道数为in_channels/groups。每组需要重复计算out_channels/(in_channels/groups)次。
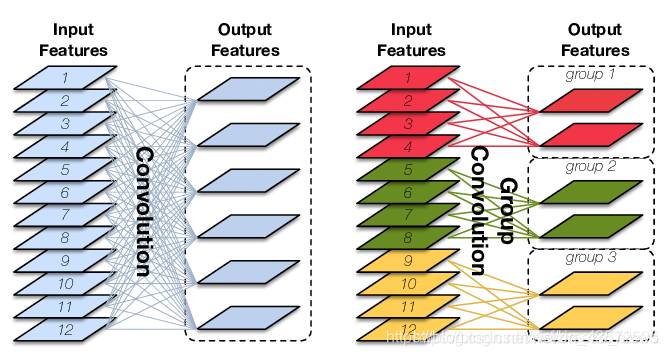
-
bias:是否将一个学习到的 bias 增加输出中,默认是 True
原理
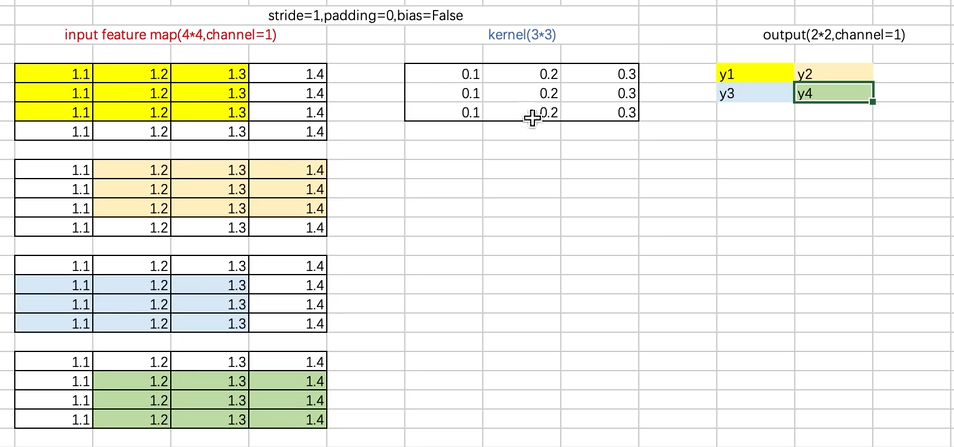
实例
1 | class CNN(nn.Module): |
nn.MaxPool2d
函数原型
1 | class torch.nn.MaxPool2d( |
参数含义
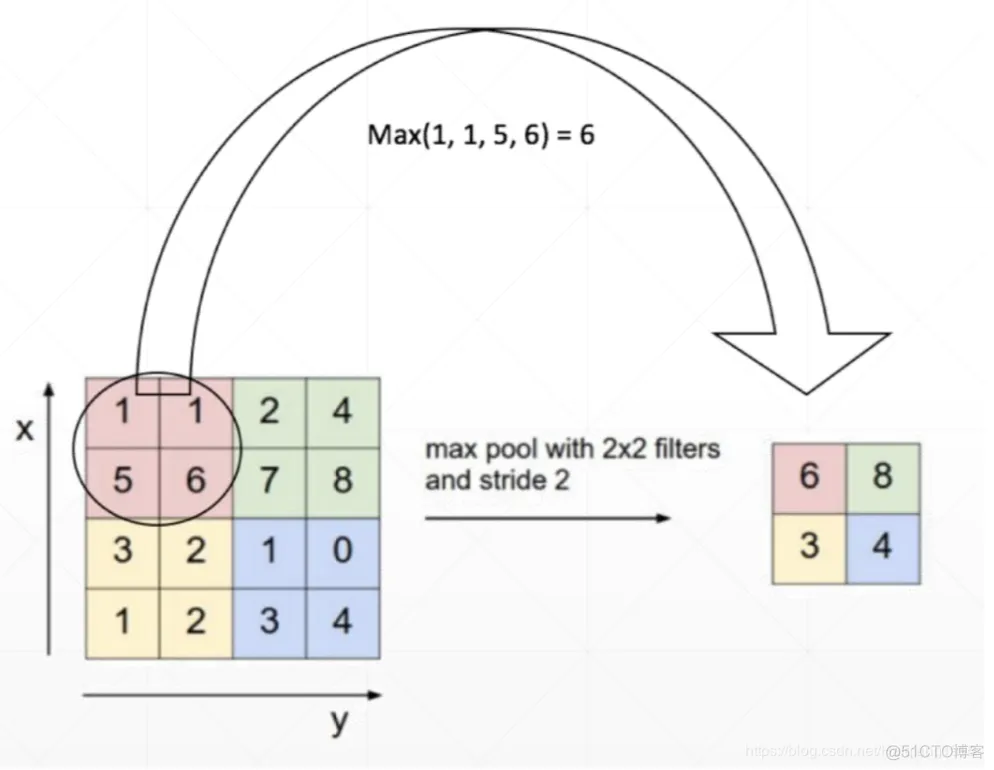
- kernel_size:可以看做是一个滑动窗口,这个窗口的大小由自己指定,如果输入是单个值,例如 3 ,那么窗口的大小就是3×3,还可以输入元组,例如 (3, 2) ,那么窗口大小就是 3 × 2 。
- stride:如果不指定这个参数,那么默认步长跟最大池化窗口大小一致。如果指定了参数,那么将按照我们指定的参数进行滑动。例如
stride=(2,3), 那么窗口将每次向右滑动三个元素位置,或者向下滑动两个元素位置。 - padding:池化填充值,默认值为0。只能是一个整数或者包含一个或两个整数的元组,为一个整数或者包含一个整数的tuple/list,则会分别在输入的上下左右四个方向进行padding次的填充;为一个包含两个整数的tuple/list,则会在输入的上下进行padding[0]次的填充,在输入的左右进行padding[1]次的填充。
- dilation:卷积核中各个元素之间的间隔大小。
- return_indices: 若为True,将会同时返回最大池化的结果和索引。
- ceil_mode:如果等于True,计算输出数据大小的时候,会使用向上取整,代替默认的向下取整的操作。
原理
实例
1 | # pool of square window of size=3, stride=2 |
评论