
POST:Fine-tuning - 训练和推理(Training vs Inference)
POST
[Fine-tuning - 训练和推理(Training vs Inference)](一文彻底搞懂Fine-tuning - 训练和推理(Training vs Inference) (qq.com))
机器学习全过程
- 收集数据
- 数据准备
- 选择模型
- 训练
- 评估
- 参数调整
- 预估
模型训练过程通常包括以下几个步骤:
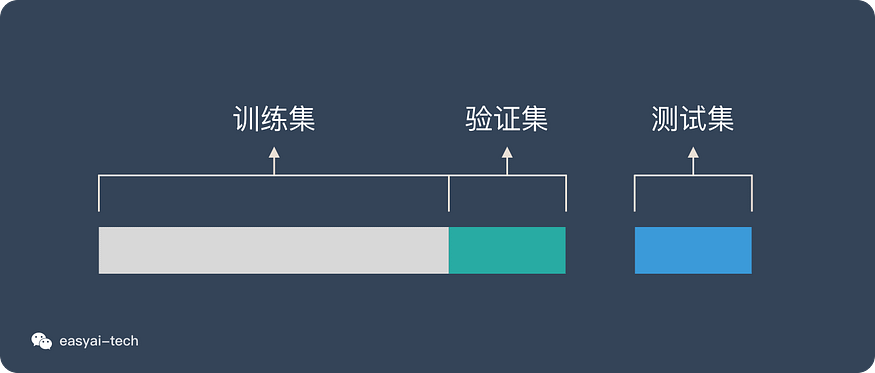
- 数据准备:收集并准备训练数据,包括数据清洗、标注、归一化、分割成训练集和验证集(有时还有测试集)等。
- 模型选择:根据任务需求和数据特性选择合适的模型架构。这可能是一个简单的线性回归模型,也可能是一个复杂的深度神经网络。
- 参数初始化:为模型的参数(如权重和偏置)赋予初始值。这些初始值通常是随机生成的,但也可以是预先设计的。
- 前向传播:将训练数据输入到模型中,通过模型的各层进行计算,得到模型的预测输出。
- 损失计算:计算模型的预测输出与真实输出之间的差异,即损失值。
- 反向传播:根据损失值,使用梯度下降等优化算法计算模型中每个参数的梯度,并将这些梯度反向传播回模型的每一层。
- 参数更新:使用梯度来更新模型的参数,以减少损失值。
- 迭代训练:重复执行前向传播、损失计算、反向传播和参数更新的过程,直到满足某个停止条件(如损失值降低到一定阈值以下,或达到预设的训练轮次)。
概念辨析
-
模型训练
通过大量数据优化模型参数以学习数据特征的过程。
-
模型推理
利用训练好的模型对新数据进行高效准确的处理以得出结论的过程。
-
普通机器学习
在机器学习模型中,通常需要人工参与到特征提取的过程中,这个过程称为特征工程,它对机器学习模型的性能有着至关重要的影响。
-
深度学习模型
自动从原始数据中学习并提取有用的特征,而无需人工干预。深度学习模型通过构建多层神经网络,每一层都能够从前一层提取更高级别的特征。
-
数据训练集
主要在训练阶段使用。
-
数据验证集
模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集(Validation Dataset)来看看模型在新数据(验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。
主要在评估和参数调整阶段使用。验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
-
数据测试集
主要在评估阶段使用。
评论