
Papers:HPN
Alibaba HPN: A Data Center Network for Large Language Model Training
概念/名词
Equal-Cost Multi-Path (ECMP)
一种网络负载均衡技术,用于通过多条具有相同代价的路径转发数据包,从而提升网络带宽和容错性。
-
多路径选择:当从源到目的地有多条路径,而且这些路径的代价(通常根据跳数、带宽、延迟等计算)相同,ECMP 允许网络设备(如路由器或交换机)同时使用多条路径进行数据转发。
-
流量分配:ECMP 通过哈希算法来分配流量。哈希算法会根据数据包(网络设备可能需要转发多个数据包)的特定字段(如源地址、目的地址、源端口、目的端口等)生成一个哈希值,然后将数据包分配到这些等价路径中的其中一条。哈希算法的目的是尽量保证数据包流的一致性,使同一个流(例如 TCP 连接)始终走同一条路径,以避免乱序问题。
-
负载均衡:ECMP 通过在多条路径上分发数据流,达到负载均衡的效果,进而提升网络的吞吐量和资源利用率。
-
优点
带宽扩展:通过使用多条路径,网络带宽可以得到有效扩展。
容错性:如果一条路径出现故障,ECMP 可以快速切换到其他等价路径,不影响整体网络的连通性。
效率提高:ECMP 能在不增加复杂度的情况下,充分利用现有的网络资源。
-
问题:Hash Polarization
Hash Polarization
由于哈希算法的偏差,流量可能集中在某几条路径上,导致流量分布不均匀,无法达到理想的负载均衡。这在大规模数据中心或复杂网络拓扑中尤为明显。
- 数据包特征分布不均匀: 哈希算法依赖于输入数据的特征(例如 IP 地址、端口号等)来计算哈希值。如果输入数据的特征不够随机,可能导致某些特定特征(如某些 IP 地址或端口号)反复映射到同一个哈希值,从而使数据流集中在少数几条路径上。这样,虽然有多条等价路径,但只有部分路径承载了大量流量,其他路径的利用率较低。
- 哈希函数设计缺陷: 理论上,理想的哈希函数应该均匀地将输入映射到不同的输出,但在实际应用中,哈希函数可能存在偏差。某些哈希函数的设计可能无法充分散列输入数据,导致不同路径上的流量分配不均。
- 数据流类型单一: 如果大部分流量来自于相同或类似的源/目的 IP 地址和端口号,哈希算法生成的哈希值会高度集中,进一步加剧流量分布的失衡。这种情况下,即使有多条路径,哈希算法仍然会反复选择某几条路径。
Clos架构
《A scalable, commodity data center network architecture》明确的提出了一种三级的,被称之为胖树(Fat-Tree)的 CLOS 网络架构,标志着 CLOS 正式进入数据中心网络架构领域,这是 CLOS 网络模型的第三次应用。
Clos起源
下图展示了一个简单的三级互联架构,包括输入级(左)、中间级、输出级(右)。每个矩形表示一个转发单元,也是一个子模块。
设m为子模块的输入端口数,n为子模块的输出端口数,r为每一级的子模块数。经过合理重排,只要满足,那么对任意的输入到输出,总能找到一条无阻塞的通路。
:表示第一级的子模块的输入端口数
:表示第二级的子模块的输入端口数
:表示第三级的子模块的输入端口数
:表示第一级的子模块的输出端口数
:表示第二级的子模块的输出端口数
:表示第三级的子模块的输出端口数
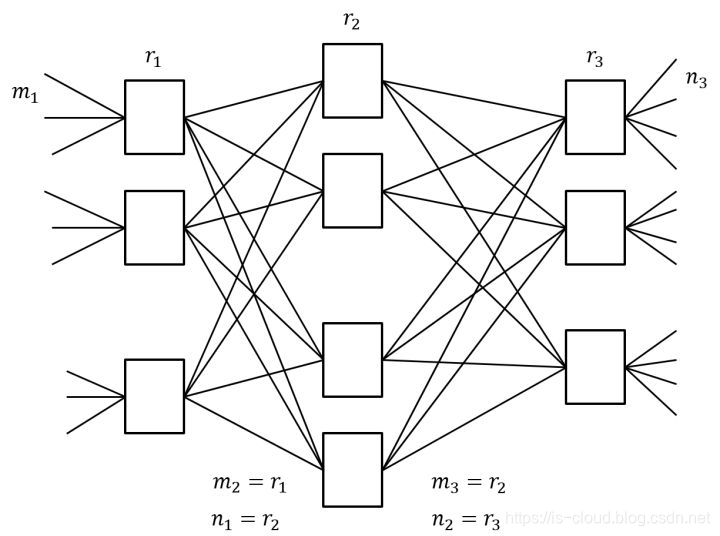
核心思想:用多个小规模、低成本的单元构建复杂,大规模的网络。
Switch Fabric
交换机内部连接输入输出的端口,最简单的 Switch Fabric 架构是 Crossbar 模型,这是一个开关矩阵,每一个 Crosspoint(交点)都是一个开关,交换机通过控制开关来完成输入到特定输出的转发。一个 Crossbar 模型如下所示:
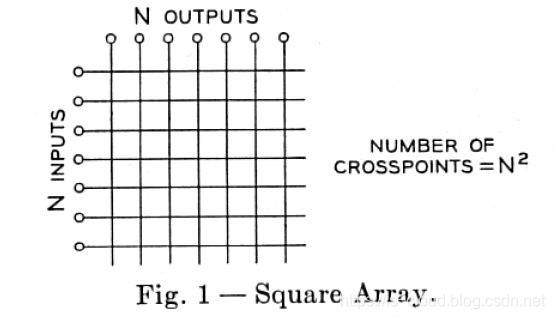
随着网络规模的发展,交换机的端口数量逐渐增多。Crossbar 模型的交换机的开关密度,也随交换机端口数量 N 呈 O(N^2) 增长。在高密度端口的交换机上,继续采用 Crossbar 模型性价比越来越低。大约在 1990 年代,CLOS 架构被应用到 Switch Fabric。应用 CLOS 架构的交换机的开关密度,与交换机端口数量 N 的关系是 O(N^(3/2)),所以在 N 较大时,CLOS 模型能降低交换机内部的开关密度。这是 CLOS 网络模型的第二次应用。
Crossbar 模型中的每个输入端口都需要和每个输出端口直接相连,因此随着交换机端口数 N 增加,所需要的连接数急剧增长。例如,4 个端口需要 16 条连接,8 个端口需要 64 条连接。换句话说,端口数 N 每增加一倍,开关密度增加四倍(即 O(N²) 增长)。
Clos 架构通过分层处理交换任务,避免了 Crossbar 模型中每个输入端口与每个输出端口的直接连接需求,从而将开关密度从 O(N²) 降低到 O(N^(3/2))。这种复杂度的降低主要是通过分布式交换来实现的
胖树(Fat-Tree)型网络架构
为了实现网络带宽的无收敛,Fat-Tree 中的每个节点(根节点除外)都需要保证上行带宽和下行带宽相等,并且每个节点都要提供对接入带宽的线速转发的能力。
下图是一个 2 元 4 层 Fat-Tree 的物理结构示例(2 元:每个叶子交换机接入 2 台终端;4 层:网络中的交换机分为 4 层),其使用的所有物理交换机都是完全相同的。
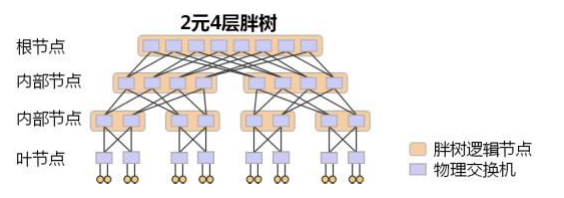
每个叶子节点就是一台物理交换机,接入 2 台终端;上面一层的内部节点,则是每个逻辑节点由 2 台物理交换机组成;再往上面一层则每个逻辑节点由 4 台物理交换机组成;根节点一共有 8 台物理交换机。这样,任意一个逻辑节点,下行带宽和上行带宽是完全一致的。这保证了整个网络带宽是无收敛的。同时我们还可以看到,对于根节点,有一半的带宽并没有被用于下行接入,这是 Fat-Tree 为了支持弹性扩展,而为根节点预留的上行带宽,通过把 Fat-Tree 向根部继续延伸,即可实现网络规模的弹性扩展。
对比根节点和非根节点可知,如内部节点,其中每台交换机上行下行各有两条链路,而根节点中的交换机只有两条下行链路,没有上行,所以说“对于根节点,有一半的带宽并没有被用于下行接入”,为扩展预留了空间。
假设一个k-ary(每个节点有不超过 k 个子节点)的三层 Fat-Tree 拓扑,下图展示了k=4的情况。连在同一个接入交换机下的服务器处于同一个子网,他们之间的通信走二层报文交换。不同接入交换机下的服务器通信,需要走路由。
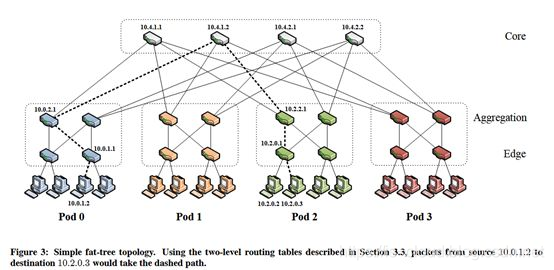
- POD:表示网络结构中的一个基本构建单元。每个 POD 是一个包含接入层和汇聚层交换机的小型子网络(即图中下层的一个矩形框),它负责连接终端服务器并通过汇聚交换机与网络的核心交换机层进行通信。
- 核心交换机个数:
- POD个数:
- 每个POD汇聚交换机(内部节点):
- 每个POD接口交换机(叶节点):
- 每个接入交换机连接的终端服务器:
- 每个接入交换机剩余个口连接 POD 内个汇聚交换机,每台核心交换机的第 i 个端口连接到第 i 个 POD,所有交换机均采用 k-port switch。
缺陷
- 扩展规模在理论上受限于核心层交换机的端口数目
- POD 内部,容错性能差,对底层交换设备故障非常敏感,当底层交换设备故障时,难以保证服务质量
- 网络不能很好的支持 One-to-All及 All-to-All 网络通信模式,不利于部署 MapReduce、Dryad 等高性能分布式应用
- 交换机与服务器的比值较大,在一定程度上使得网络设备成本依然很高
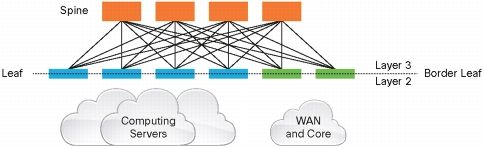
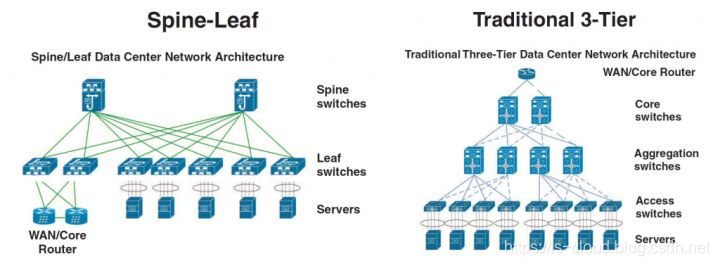
叶脊(Spine-Leaf)网络架构
Spine-Leaf 网络架构,也称为分布式核心网络,由于这种网络架构来源于交换机内部的 Switch Fabric,因此也被称为 Fabric 网络架构,同属于 CLOS 网络模型。事实已经证明,Spine-Leaf 网络架构可以提供高带宽、低延迟、非阻塞的服务器到服务器连接。
Leaf Spine 只有两层,这是因为:网络架构中的设备基本都是双向流量,输入设备同时也是输出设备,因此三级 CLOS 沿着中间层对折,就得到了两层的网络架构。可以看出传统的三层网络架构是垂直的结构,而 Spine-Leaf 网络架构是扁平的结构,从结构上看,Spine-Leaf 架构更易于水平扩展。
L3 交换机(Layer 3 Switch)和 L2 交换机(Layer 2 Switch)主要的区别在于它们在网络协议栈中处理数据的层级不同。
Switch:
- Leaf Switch:相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。与接入交换机的区别在于 L2/L3 网络的分界点现在在 Leaf 交换机上了。Leaf 交换机之上是三层网络,Leaf 交换机之下都是个独立的 L2 广播域。
- Spine Switch:相当于核心交换机。Spine 和 Leaf 交换机之间通过 ECMP(Equal Cost Multi Path)动态选择多条路径。区别在于,Spine 交换机现在只是为 Leaf 交换机提供一个弹性的 L3 路由网络,数据中心的南北流量可以不用直接从 Spine 交换机发出,一般来说,南北流量可以从与 Leaf 交换机并行的交换机(edge switch)再接到 WAN router 出去。
Fabric 中的 Leaf 层由接入交换机组成,用于接入服务器,Spine 层是网络的骨干(Backbone),负责将所有的 Leaf 连接起来。每个低层级的 Leaf 交换机都会连接到每个高层级的 Spine 交换机上,即每个 Leaf 交换机的上行链路数等于 Spine 交换机数量,同样,每个 Spine 交换机的下行链路数等于 Leaf 交换机的数量,形成一个 Full-Mesh 拓扑。当 Leaf 层的接入端口和上行链路都没有瓶颈时,这个架构就实现了无阻塞(Nonblocking)。并且,因为任意跨 Leaf 的两台服务器的连接,都会经过相同数量的设备,所以保证了延迟是可预测的,因为一个包只需要经过一个 Spine 和另一个 Leaf 就可以到达目的端。
因为 Fabric 中的每个 Leaf 都会连接到每个 Spine,所以,如果一个 Spine 挂了,数据中心的吞吐性能只会有轻微的下降(Slightly Degrade)。如果某个链路的流量被打满了,Spline-Leaf 的扩容过程也很简单:添加一个 Spine 交换机就可以扩展每个 Leaf 的上行链路,增大了 Leaf 和 Spine 之间的带宽,缓解了链路被打爆的问题。如果接入层的端口数量成为了瓶颈,那就直接添加一个新的 Leaf,然后将其连接到每个 Spine 并做相应的配置即可。这种易于扩展(Ease of Expansion)的特性优化了 IT 部门扩展网络的过程。
Top of Rack(ToR)
TOR(Top of Rack)指的是在每个服务器机柜上部署1~2台交换机,服务器直接接入到本机柜的交换机上,实现服务器与交换机在机柜内的互联。虽然从字面上看,Top of Rack指的是“机柜顶部”,但实际TOR的核心在于将交换机部署在服务器机柜内,既可以部署在机柜顶部,也可以部署在机柜的中部(Middle of Rack)或底部(Bottom of Rack),如图所示。通常而言,将交换机部署在机柜顶部是最有利于走线的,因此这种架构应用最多。
单点故障
主要是因为 ToR 交换机在数据中心网络中通常是第一层接入交换设备,它连接了一个机架中的所有服务器。因此,一旦 ToR 交换机出现故障,连接到该交换机的所有服务器都将失去与网络的连接,导致整台机架中的服务中断。
同步需求: LLM训练中的同步要求所有要求 GPU 以同步方式完成迭代。如果某一个GPU或交换机出现故障,可能会导致整个训练过程的同步被打断,影响训练的稳定性和效率。
单点故障: 在数据中心的网络架构中,ToR交换机通常负责连接同一机架中的所有服务器(或GPU)。如果ToR交换机发生故障,这个机架中的所有设备可能都会受到影响,导致训练过程的中断。
南北流量/东西流量
云计算数据中心环境中网络流量的两种模式。
- 南北向流量是指数据从网络或数据中心的上层(例如互联网)流向下层的流量,或者从下层流向上层的流量。这包括用户访问网站、下载文件、发送电子邮件等活动。南北向流量通常是指与外部网络之间的数据传输。
- 东西向流量是指在网络或数据中心内部在水平方向上的数据传输量。它涉及服务器之间的通信、内部数据传输、数据库访问等。东西向流量通常指在数据中心内部或内部网络之间的数据传输。
研究背景与问题
LLM训练需要大规模的分布式训练集群,大量GPU。在这样的条件下,由于其本身的特性,LLM对数据中心网络提出了新的要求。
-
Traffic Patterns
-
从
entropy和traffic上看,LLM训练与一般云计算模式存在不同在网络中,
entropy(熵)通常反映了traffic(流量)的多样性和不可预测性。熵越高,意味着流量的模式更加不规则,网络的行为更加复杂,负载在网络中的分布不均匀性更高。反之,低熵意味着网络流量比较集中或模式化,容易预测和管理。- 云计算平台上通常存在大量的小流量 (Mice Flows) 和少量的大流量 (Elephant Flows)。这些小流量占据了绝大多数的网络流量,它们的传输数据量较小且时间短,典型情况下并不会占满网络接口卡 (NIC) 的带宽。因此,每个流的带宽利用率较低,通常低于 20% 的 NIC 容量。
- 在 LLM 训练中,涉及的节点数较多,但每个节点之间的通信流量相对较少且集中。相比于云计算环境中众多的小流量,LLM 训练通常只涉及几个主要流,这些流量往往集中在少数的计算节点之间进行大规模数据交换。LLM 训练涉及大量的数据传输,特别是在模型参数同步和梯度传输时,这些传输操作通常在每次迭代完成后进行,并且是短时间内的大规模数据交换。因此,流量表现为周期性的突发。由于 LLM 训练产生的流量虽然少但数据量大,当突发流量发生时,网络需要在短时间内处理大量的数据传输,导致网络资源(如 NIC 和链路带宽)被高效利用。
-
由于上述原因,传统数据中心网络使用的ECMP负载均衡方案不再适合于LLM训练场景。
high entropy:意味着有大量随机的、小流量,流量目标和源头不固定,哈希算法能够有效地分散这些小流量,均衡多条路径的负载。low utilization:每个流量的带宽需求较小,使得即使多个流量分配到同一条路径,也不会导致严重的拥塞或超载。low entropy & high utilization:如果有多个高利用率的流被哈希分配到同一条路径,由于这些流量占用了大部分带宽资源,容易造成路径拥堵。高利用率流量的数量少但带宽需求大,这意味着即使 ECMP 尝试分配流量到不同路径,也有可能造成某些路径承载过多流量,而其他路径利用率较低。
-
-
Higher sensitivity to faults, especially singlepoint failures
-
LLM训练的同步性
LLM训练中,GPUs需要合作完成一系列迭代,是一个同步的过程(上传、下载、聚合梯度),任何GPU的异常都可能使得训练进程被拖慢甚至崩溃。因此,LLM训练比传统云计算过程对故障更为敏感。
-
ToR单点故障
ToR 交换机在数据中心网络中通常是第一层接入交换设备,它连接了一个机架中的所有服务器。因此,一旦 ToR 交换机出现故障,连接到该交换机的所有服务器都将失去与网络的连接,导致整台机架中的服务中断。
-
本文贡献
HPN:为LLM训练服务的高性能网络
-
提出了一个全新的ToR部署方案(
i.e.“即”, the non-stacked dual-ToR design),通过取消两交换机之间的直接同步机制,每台ToR交换机独立处理流量,进一步提高了网络架构的稳定性,解决ToR单点故障问题。传统的双ToR设计是由交换机厂商提出的,通常采用堆叠方式,即两台ToR交换机直接相互连接,并通过同步机制(如共享配置、状态信息等)来实现。
- 优点:这种设计确保了两台ToR交换机协同工作,确保机架的高可用性。服务器可以同时连接两台ToR交换机,当一台ToR故障时,另一台可以立即接管网络流量。
缺点:这种堆叠方式依赖两台交换机之间的直接同步。如果同步机制出现问题,或者同步链路故障,可能导致两台ToR之间的不一致,反而会增加故障的可能性。
-
通过采用51.2Tbps交换芯片(这一技术改进可以支持极高的数据吞吐量)、利用轨道优化网络,网络接入层能够容纳1K个GPU,其中绝大部分(96.3%)的训练任务能够获得最佳的网络性能。
-
HPN能够在2层双平面架构中支持15K个GPU,这与传统的大规模训练集群规模一致,而无需使用复杂的3层Clos架构。
- 使用2层双平面架构的另一个好处是**显著减少了ECMP(等价多路径)*的发生。**ECMP**通常用于在多个等价路径之间均衡流量,但在一些情况下可能会导致*哈希极化,即流量分配不均。
- 在选择用于传输大流量(如elephant flows)的理想路径时,HPN 的设计还减少了1-2个数量级的路径搜索空间。这使得网络在处理大数据流时更加高效,能够更快找到合适的传输路径,避免拥塞。